הבלוג של ארתיום
בלוג על לינוקס, תוכנה חופשית, מוזיקה, סלסה, ומה לא!
האם בסיס הנתונים הוא צוואר הבקבוק של המערכת?
אחת הדעות המקובלות בקרב מפתח Web היא שבסיס הנתונים הוא צוואר בקבוק של המערכות. בסופו של דבר, אם יש המון נתונים והחיפוש לוקח 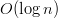 אז אין מה לעשות. ברמה תיאורתית זה נכון.
אז אין מה לעשות. ברמה תיאורתית זה נכון.
אם יש לך בסיס נתונים של 1,000,000Gb (שזה 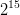 ) אז כנראה החזקה מספיק גדולה ואין משמעות לטכנולוגיות אחרות... השאלה היא האם זה נכון?
) אז כנראה החזקה מספיק גדולה ואין משמעות לטכנולוגיות אחרות... השאלה היא האם זה נכון?
כידוע, מודל הסיבוכיות הוא עובד יפה כשמדובר במספרים גדולים מספיק ונוהג להתעלם מקבועים. מסתבר שהקבועים הם מספיק חשובים.
כדי להבין את זה, נקח כדוגמה את אחד הפרוייקטי ה־web הגדולים --- wikipedia או ליתר דיוק את חוות השרתים של wikimedia.
נתונים גולמיים:
- בחוות השרתים נמצאים כ־300 שרתים שונים.
- מתוכם במסלול הראשי:
- 95 שרתי Squid -- מה שנקרא Upstream cache שנותנים מענה לכ־78% מכל הבקשות (hit ratio שלהם).
- 144 שרתי Apache+PHP. שנותנים מענה ל־25% הנותרים.
- 20 שרתי MySQL שונים הרצים בתצורות Master Slave השונות.
- השרתים האחרים נותנים מענה לחיפוש, טיפול בקבצים סטטיים ועוד.
- מנגנון memcached משפרים ב־7% הנוספים את היעילות של יצירת התוכן ע"י שרתי Apache.
לכן כיצד שרתי SQL יכולים להוות צוואר בקבוק של המערכת אם הם מהווים פחות מ־10% מכל השרתים הקיימים בחווה? בהנחה שהמערכת שנבנתה ע"י media wiki היא מאוזנת, ברור לנו שרוב העומס החישובי נופל דווקא על שרתי apache המריצים את PHP.
אז האם באמת בסיס הנתונים הוא צוואר הבקבוק?

{kind=link}
תגובות
שרת הSQL יכול להיות בהחלט צוואר הבקבוק הנושא הוא לא כמה משאבים הוא צורך, אלא כמה זמן לוקח לו לחפש משהו כשאתה שולח בקשה לשרת WEB, השרת עובד בצורה לינארית, הוא מגיע למקום בו הוא צריך לבצע את שאילתת הSQL, שולח את הבקשה לשרת לשרת יכול לקחת זמן מסויים, בזמן הזה החיבור של הלקוח לשרת הWEB תופס את המשאבים הדרושים לכך.
ניצול משאבים באופן יעיל זה כבר משהו אחר. לדעתי רוב המערכות המתוכנתות היום אינן יודעות לעבוד בתצורת משאבים נמוכה יחסית, בעיקר כי מדובר בצורת עבודה של "קודם נוציא את המידע, אחר נציג אותו", שאומר בתאכלס שמחזיקים את כל המידע הדרוש, ואת המשתנים השונים בזכרון זמן רב.
בנוסף, כשיש לך מערכת גדולה, חשוב ליצור מערכת קאשינג שתעבוד כמו שצריך, ובכך אתה חוסך את הקריאה לשרת הSQL, מכיוון שקריאה לקובץ מהירה יותר מאשר קריאה לתוצאת SQL.
בקשר לויקיפדיה, למערכת עם כניסות בכמות שלה, הייתי פשוט יוצר דפים סטטיים ( ואין סיבה שלא ), לכל ערך צריך להיות דף HTML סטטי ( שיווצר לאחר העירכה ) ובך יחסכו המון משאבים, גם את דפי העריכה הייתי הופך לדפי סטטיים ( אפשר עם קצת תחכום ). במצב כזה, האתר יסחוב הרבה יותר מכיוון שבבקושי יש צורך משאבים בכדי להציג HTML סטטי ( אפשר אפילו לא להגיש אותו דרך אפאצ'י אלא דרך שירות קליל ).
אני אקצר ואגיד כי רוב המערכות כבדות ועובדות בצורה גוזלת משאבים בעיקר בגלל תכנון לקוי. והמסר הכי חשוב אולי - תתחילו לחשוב, כשאתם בונים אתר בצורה מסויימת תתחילו לחשוב, מה היתרונות, מה החסרונות, איפה אפשר לשפר, כמה זמן כל דבר נשאר בזכרון, איך אנחנו מצמצמים זאת, ואיך אפשר לבנות בצורה מאורגנת מספיק כך שיהיה אפשר לתחזק את המערכת בצורה טובה.
יום טוב :) רם מתתיהו
אתה מפספס נקודה חשובה - אותם 144 שרתים שמריצים Apache+PHP לא יכולים לעשות דבר ללא גישה לשרתי בסיסי הנתונים, כך ש־25% מבקשות הנתונים מוויקיפדיה תלויות למעשה בשרתי MySQL (אם נתעלם מ־memcached, שאני לא בטוח שהוא מצליח לבטל את הקריאות לבסיסי הנתונים).
אם אני מבין לאן מובילה הביקורת שלכם אז: יכולתם לתכנן לתכנן מערכת ויקיפדיה חדשה באמצעות כלים שלא היו כשפותחה ויקיפדיה שתהיה יעילה יותר ושלא תשתמש בLAMP?
תומר, שוב, לא חובה שכל חיבור ידרוש חיבורים לשרת הSQL ראה תגובתי מעלה. אפשר הבחלט ליצור דפים סטטיים ולהגיש אותם אבגד, אין היום אפשרויות מיוחדות שלא היו קיימות אז ( טוב, יכול להיות שיש, אבל לא צריך אותן בשביל תכנון נכון )
קול ספוט
זה נכון רק במקרה של מערכת סינכרונית. רוב שרתי ה־web המודרניים כמו lighttpd או nginx רצים בצורה אסינכרונית. כשמדובר במערכת התוכן בד"כ יש חוט חישוב שמחכה, אבל בד"כ אפשר ליצור מספר גדול של חוטי חישוב כך שהמערכת תעבוד מספיק טוב.
אני מניח שפה אתה טועה. אתה מניח הנחה מאוד חזקה שגישה לבסיס הנתונים היא פחות יעילה מגישה למערכת קבצים. בנוסף, לקבצים סטטיים יש הרבה מגרעות והעיקרית היא קושי בעדכון גורף.
אני חושב שקשה להגיד את זה על ויקיפדיה שמריצה מנגנוני cache כבדים ומהווה אחד האתרים הנפצים בעולם שיש לה תכנון לקוי, זה מטעה, בנוסף שיש הרבה מערכות כבדות הבנויות בצורה דומה.
אבגד
ברור ש־apache ללא mysql חזר ערך כמו ש־mysql חסר ערך ללא apache. אבל... השאלה איפה יותר משאבים מתבזבזים?
תומר
אני לא מבקר, אלא אומר שהדעה הרווחת כי שינוי טכנולוגית צד השרת (שפת תכנות בפרט) היא חסרת משמעות כי צוואר הבקבוק הוא תמיד בסיס הנתונים. זה הכל. לא צריך להיות גאון גדול כדי להבין מדוע אני מנסה להדגיש את המסקנה בהקשר הפרוייקטים שאני עובד עליהם.
כל מה שאני רוצה להגיד... Be Open Minded.
בשביל לא להסתובב סביב הנקודה כל הזמן, הבעיה הגדולה היא מאז ומתמיד I/O (חשוב לזכור שגם שקעים הם סוג של I/O).
שאילתות בחירה שרצות כדרך קבע נמצאות בד"כ בזכרון (אם זה מבחינת byte code או המצביע למידע שהן צריכות להחזיר), ולכן הזמן שלוקח להם להתבצע קצר יותר מאשר אותה שאילתה שרצה פעם ראשונה.
מערכת קבצים לא בהכרח פחות טובה ממסד נתונים, זה תלוי בגורמים שונים. למשל מה גודל המידע, כמה פעמים הוא נקרא ואיזה פעולות אחרות מבססות עליו. אין ספק שהזכרון הוא האמצעי הכי מהיר, אבל מה לעשות שהוא הכי מוגבל מכל השאר מבחינת הזמינות שלו.
העניין הוא שמאוד קשה להגיד איך הצוואר בקבוק של מסדי נתונים מתבצע, כי זה תלוי בהרבה גורמים אחרים כדוגמת מערכת קבצים, העומס הכללי על המכונה, כמות המידע והשאילתות, מבנה הטבלאות, סוג מסד הנתונים, מנוע מסד הנתונים, קוד שמשתמש במסד הנתונים, כמות פעולות I/O שהוא מבצע ועוד הרבה.
אבל צריך להבין שהוא גם סוג של צוואר בקבוק, ואם לא יודעים לטפל בו נכון, אז הוא הצוואר שיכול להבדיל בין אפקט סלאשדוקט לבין מערכת שממשיכה לרוץ (כמובן שזה לא מדוייק, אבל זה יכול לשנות הרבה).
ההיסק כאן מוטעה לדעתי. המחשבה צריכה להיות: תראה כמה שרתים מופעלים כדי למנוע עיבוד המצריך גישה לשרתי בסיסי הנתונים, מה גם שגידול לינארי בבסיסי נתונים לא ייתן בהכרח את הגידול המקווה (להבדיל משאר השרתים, פה יש גם לדאוג לסנכרון).
הנה המספרים מווטסאפ, ממויינים לפי cpu time: PID USER PR S %CPU %MEM TIME+ COMMAND 4179 mysql 16 S 63 35.3 283:22.54 mysqld 23942 www-data 16 S 0 0.7 12:05.44 python 13339 www-data 16 S 0 0.3 6:40.32 php4-cgi 23848 www-data 25 S 0 0.1 6:29.53 php4-cgi 23845 www-data 25 S 0 0.1 6:28.57 php4-cgi 13343 www-data 16 S 0 0.3 6:19.32 php4-cgi 23798 www-data 16 S 0 0.1 6:15.00 php4-cgi 23808 www-data 16 S 0 0.1 6:13.73 php4-cgi 23828 www-data 16 S 0 0.1 6:12.35 php4-cgi 23834 www-data 15 S 0 0.1 6:11.67 php4-cgi 23807 www-data 16 S 0 0.1 6:11.41 php4-cgi 13321 www-data 16 S 0 0.2 6:11.03 php4-cgi 23831 www-data 16 S 0 0.1 6:09.39 php4-cgi 13348 www-data 16 S 0 0.2 6:08.70 php4-cgi 23851 www-data 15 S 0 0.1 6:08.68 php4-cgi 23825 www-data 16 S 0 0.1 6:08.44 php4-cgi 23816 www-data 16 S 0 0.1 6:07.49 php4-cgi 23801 www-data 16 S 0 0.1 6:05.48 php4-cgi
די מדברים בעד עצמם.
אני מבין את הכוונה שלך אבל... עדיין מחצית מכל האתר מתעסק ב־PHP. שבהם דווקא כן יש גדילה לינארית.
השאלה היא האם שימוש בבסיס הנתונים של PhpNuke הוא יעיל? בוא נגיד ככה:
בכל גישה המערכת מושכת את כל הנתונים הדרושים ליצירת דף web הכוללים הגדרות כלליות, משתמשים ועוד אלף ואחד דברים שניתן לעשות להם cache בקלות ובצורה יעילה מאוד.
האם זה ניצור יעיל של משאבי בסיס הנתונים?
אפשר להמשיך. אני לא אומר שבסיס הנתונים לא יכול להוות צוואר בקבוק. אלא בתנאים של ניצול משאבים יעיל המערב כמובן cache, זה לא בהכרח נכון.
בנוסף, אתה יכול להסתכל בעוד כתבה, שד"א אתה נתת קישור אליה: מערכת עמוסה במיוחד בנויה על Django המכילה כ־11 שרתים ש־2 מתוכם זה MySQL ו־5 זה apache.
הכי מצחיק זה שאני עוד עונה לך ב-stackoverflow... וחושב "ואללה, מעניין מה ארתיום משתמש במערכת שלו..."
תזכורות להבא: לבדוק מי כותב את השאלה. http://stackoverflow.com/questions/738273/open-source-c-c-embedded-web-server/738299#738299
במה אתה משתמש כעת?
בכל דבר שתומך ב־cgi, fastcgi או scgi שזה יכול להיות lighttpd, apache, nginx או thttpd. כולם עובדים.
בגדול בחירת השרת תלויה בדרישות שלך. אני לא מממש שרת http ספציפי כי אני חושב שעדיף להשאיר את המשימה לטובים ממך שיודעים לעשות את עבודה ולדאוג להרבה מאוד דברים שהם מחוץ לתחום של web framework.
אני המלצתי להסתכל על הקוד של Boost.Asio כי אני יודע ש־Wt (הפרויקט המתחרה ל־cppcms) השתמשו בו כדי לבנות שרת עצמאי (למרות שגם הם תומכים ב־fastcgi).
חוץ מזה, ביום־יום אני משתמש ב־lighty כי הוא הכי קל להגדרה ובא כברירת מחדל עם כל צורות (f|s)cgi שאני צריך; וגם מימוש שלהם הוא ברמה די טובה, לפחות אחרי שהכניסו את הטלאי שלי עבור scgi.
כך למשל, lighty הוא היחיד שתומך ב־process spawning עבור scgi וגם תומך ב־unix domain socet עבורו. מה שמאפשר לי כלל להמנע משימוש ספריית צד ג' שנותנת תמיכה ב־fastcgi כשאין לי כוח לאסוף את כל התלויות.
לנסות להוכיח נקודה ע"י ספירת שרתים זהה לניסיון להוכיח כי מערכת אחת בטוחה יותר מהשניה ע"י ספירת עדכוני אבטחה.
מצד אחד אתה בא להפריך את נושא אי חשיבות שפת תכנות מאחר ובסיס הנתונים אינו בהכרח צוואר בקבוק מצד שני אתה מטיל ספק ביעילות פוסט ניוק מאחר והיא כותבת מידע לבסיס הנתונים במקום להשתמש בטכניקות אחרות ? אתה לא קולט את הסתירה ?
גם מהתגובה נראה שאתה לא כל כך מכיר את המערכות דמויות הניוק, הן הרבה יותר מורכבות (ממש לא שתיים שלוש שאילתות) אולי תחפור קצת בקוד שלהן.
אני גם רוצה לראות אותך מוצא פתרון יעיל יותר אפילו למקרה פשוט של איסוף סטטיסטיקה, במסגרת הפרמטרים ש-PN עומד בהם, הכי חשוב: התקנה על חשבונות ההוסטינג הכי פשוטים, ללא shell, לא memcache, ללא שליטה על שרת http ושאר פינוקים. יש רק אפשרות להעלות קבצים, גישה אליהם מדפדפן ובסיס נתונים. כמו כן המידע הנוסף לא רק סופר כניסות אלא פעילות לפי ימים, חודשים, שעות ביממה.
למה אני בכלל צריך להתחשב בזה ? אני צריך לכתוב מידע וכזה שלא יילך לאיבוד ושיהיה מעודכן תמיד (אפילו פורום פשוט צריך לעקוב אחרי כל כניסה אחרונה של המשתמשים, כדי לתת מידע מידע על פוסטים מהביקור האחרון, ולשמור בזכרון לא בא בחשבון: נפילות יגרמו למידע מוצג שגוי).
אז מה אני נאלץ לעשות (וגם מה שאתה מציע) ? להחביא את בסיס הנתונים העגלה מאחרי הררי caching אשר רק מסרבלים את האפליקציה והלוגיקה שלה (וזה עוד לפני שדיברנו על sharding ושאר טכניקות), ורק לטפל בכמות הפניות (שעשויה להיות אדירה ופעמים רבות אף מותאמת אישית לכל משתמש, כמו במקרה של curse כך ש-caching לא בדיוק עוזר).
האם זה לא בדיוק מה שרואים בכמות השרתים ? ה-database הוא סרח עודף, ולא מספיק זה, צריך לעשות שמיניות באוויר להסתירו, כי הוא צוואר הבקבוק.
אני גם לא מבין איך אתה מנסה להוכיח משהו לדוגמא מהנתונים של וויקיפדיה, כאשר ברור שברוב המוחלט של המקרים לא שפת הפיתוח עונה על הבקשות. אז אם נתחשב בדוגמא של וויקיפדיה, יש פה מצב שלוקח אף לקיצוניות רבה יותר את הנקודה שאתה מנסה להפריך: רוב הזמן שפת הפיתוח עצמה כלל לא פקטור (ולא משנה איזו היא) מאחר והיא כלל אינה מורצת.
תשמע, אין ספק שהטכניקה של שמירת כל המצב בבסיס הנתונים היא מאוד יעילה כל עוד מדובר באירוע משותף ובאתר על 1,000--2,000 כניסות ביום. השאלה היא האם הטכניקה הזו נכונה גם עבור אתרים המאוכסנים בשרתיים ייעודיים עם 100,000 כניסות ביום?
כשמפתחים תכנה אפשר להסתכל על שני הבטים של יעילות -- זמן ומקום. באירוח שיתופי בהחלט המקום הוא הקובע אין לך אפשרות לתת לכל אחד הרבה זכרון עבור cache וכד'.
מה שכן, כשאתה עובד בסביבה קצת יותר אתירת עומס הדברים משתנים. יש עיקרון מאוד פשוט: אם בתוכנה שלך אתה עושה אותו דבר מספר פעמים, אולי עדיף לשמור את התוצאה ולהשתמש בה עוד פעם.
תגיד לי, מהו downtime של השירות כתוצאה עומס יותר (למשל בגלל איזה רובוט שסוקר או בגלל הפניה מ־ynet?) כשמשתמשים בכלל לא יכולים לגשת לאתר או מקבלים timeout בגישות שלהם?
מהו downtime של האתר כתוצאה מנפילות חומרה או תכנה?
או קיי... אז מה יקרה אם כל הנתונים של המשתמשים לא יישלחו מיד לבסיס הנתונים אלא ייעדכנו פעם חצי שעה או רק במקרה שהמשתמש לא נראה באופק במשך נגיד 5 דקות; וסביר להניח שאין מה לעדכן יותר ואז לעשות עדכון מרוכז בבסיס הנתונים?
הטענה שלך היא כמו: קובץ הוא צוואר הבקבוק בגלל שבכל עדכון של משתנה אני עושה לו סריאליזציה ושופך לקובץ. אההה... אולי לא לעשות את זה?
נכון, זה מסובך, זה מצריך תכנון מורכב המסדיר בעיות בין storage לבין תהליך. אבל זה בעצם מה שנקרא תכנות. בשביל מה יש למתכנת ראש? בשביל כובע? בגלל זה מתכנת לומד 5 שנים באוניברסיטה ועוד הרבה שנים בעבודה --- כדי לחשוב על פתרונות ולא לעבוד בצורה של "תבנייות סטנדרטיות" שנותנות פתרון.
שום דבר לא יפתור תכנון לקוי.
אני חוזר ואומר. לא ש־PosteNuke בנויה בצורה לא נכונה, בהחלט בתנאים שמציבים לה היא כן. השאלה היא האם היא בנויה בצורה נכונה גם במקרים יותר "עמוסים" אולי היא צריכה לפעול אחרת?
בכל אופן, זה לא נראה לך מוזר שאתר שמייצר בממוצע 1.5 עמודים בשניה צורך 65% מזמן המעבד המבוזבזים על MySQL? זה בעידן שבו ניתן לפרוס HDTV בזמן אמת בקצב של 25 תמונות בשניה גם במחשבים עגלות, זה בזמן שמשחקי מחשב מגיעים למאות תמונות תלת מימדיות מרהיבות בשניה.
זה נראה לי פשוט לא הגיוני מה שלא תגיד.
ועכשיו נחזור לויקיפדיה שמפעילה את כל הטריקים האפשריים כדי להיות יעילה: memcached, squid, הפרדה בין שרתים המספקים תכן סטטי ודינמי עדיין דורשת 144 שרתים שכל מה שהם עושים זה לבנות דפים בעזרת PHP... זה לא נראה מגוחך?
תודה שאתה מסביר לי מה שאני צריך לעשות, מזל, לא ידעתי, אני הולך ליישם את זה. וכעת ברצינות: אני שונא דיונים שהעיקר בהם הוא המהות, אבל הצד השני מסביר לי "איך". תודה רבה, את זה אני כבר יודע.
המהות היא מדוע אני צריך בכלל ליישם דבר כזה האפליקציה שלי מורכבת מאוד גם כך, אני לא צריך לסרבל אותה עוד יותר על שטויות. אני צריך לחשוב פעם אם לכתוב מידע ל-persistence שלי ? בשנת 2009 ? אני מפתח כבר 25 שנה בצורה כזו או אחרת והטכנולוגיה עדיין מתקופת האבן.
הממ, מה ווטסאפ אומר לי היום (ויום בינוני וממוצע, יש כאלה עם יותר כניסות) עם האפליקציה הבלתי יעילה ביותר בעליל שלו:
מה הלאה ?
וואסאפ מאונדקס באופן קבוע ע"י לפחות שני מנועי חיפוש בו זמנית. זמן חוסר התגובה היחיד הוא בעת dump של בסיס הנתונים - לא קשור לאפליקציה (למספר דקות, אנחנו עושים זאת כל 4 שעות). פשש, מה כן מחזיק ? האפליקציה הבלתי יעילה וללא ה-caching הזו ?
מדוע ? כי בסיס הנתונים דפוק ? איך זה קשור לשפה דינאמית ?
הרבה רעש צלצולים וסיסמאות, הרשה לי לא להתרשם. מפתחים לומדים שנים כדי לטפל בחסרונות של טכנלוגיות שהן די מפגרות, ומה קורה ? באים מפתחים דפוקים (אלוהים עדי שהקוד של פוסט ניוק גרוע), כותבים אפליקציה בלתי יעילה, שבמקרה שלנו ישנה מאוד ולא מתוחזקת, בשפה איטית יותר מצב צולע, ללא שום caching והתחשבות בביצועים (אבל עם הרבה תכונות אחרות, לדוגמא: יכולות הרשאות מורכבות על כל מודול), והאפליקציה שלהם מטפלת בכמות כל כך גדולה של פניות ?
במחשבה שניה זה נשמע עצוב מאוד. אני מקווה שלפחות מלמדים את הנשמות המסכנות באוניברסיטה את המשמעות של premature optimization.
זו הסיבה שאני לדוגמא לא חושב אפילו על caching כשאני מפתח את האפליקציה, אלא על תכונות האפליקציה עצמה. אופטימיזציות באות רק לאחר שמזהים צווארי בקבוק ואם יש צורך. אני מעדיף קוד טוב ואפליקציה עשירה, בעלת יכולות תחזוקה ועדכון קלים במקום קוד מסורבל מראש ללא צורך. כאשר יש צורך אין בעיה להוסיף זאת אח"כ (יתרון של מערכות ושפות גמישות).
זה באמת מאכזב, חשבתי שאתה יודע שלא מסתכלים על אחוזי שימוש נקודתיים ב-top, או שהיית מעדיף שהייתי מעתיק עשירית שניה אחרי, כאשר אחוז השימוש שלו ירד ל-0 ונשאר שם ?
מרשים מאוד איך הטכנולוגיה התקדמה, לא ? HDTV במחשבים עגלות, משחקי מחשב עם מאות פריימים. אכן אני נפעם. אז מדוע בסיס נתונים מסכן לא יכול לטפל בכמה כתיבות בשניה עד כדי כך שאני צריך לערוך שמיניות באוויר כדי לעקוף אותו ? מה זה, לערוף את ראשו. תזכיר לי באיזה שפה בסיסי הנתונים האלה כתובים, בטוח שפה דינאמית, בטח איזה פייתון או רובי עגלות. מה לא ? ב-C או C++ ? לא יכול להיות, הן מהירות מאוד ?!?!? לא, זה רק בגלל שפות דינאמיות.
אני בטוח שאתה קולט את האירוניה.
מאיר, חס וחלילה, אתה לא מתאר לעצמך כמה אני מעריך את עבודתך הקשה על ווטסאפ וברור לי שבתנאים הנוכחיים אתה עושה את הדבר הטוב ביותר שניתן לעשות.
צר לי לאכזב אותך אבל כן. כי אפילו שחוק המור עובד, גם הדרישות עולות... כך שמה שלא יהיה צריך לחשוב על זה.
מאיפה אתה חושב שלקחתי את המספר ;)
לא מסכים שבסיס הנתונים דפוק. אלא האופן שבו משתמשים בו.
זה נושא אחר. אם אתה תשתמש לא נכון בבסיס הנתונים ברור הוא יהיה צוואר הבקבוק גם אם אתה כותב ב־bash. מצד שני, אם אתה משתמש בו בצורה יעילה אז הדברים משתנים.
אתה חושב ש־1.5 שאילתה בשניה זה הרבה???
ברור, ואף אחד לא מתווכח על זה.
ברור שלא צריך לקחת ווטסאפ לשכתב אותו כדי שהוא יצרוך 1% של משאבים במקום 50%. השאלה היא מה יקרה אם מחשב כמות הפניות תגדל מ־100,000 ל־1,000,000? או 10,000,000 (הלוואי ד"א). כשזה יקרה אז יהיה צורך באופטימיזציה.
דווקא כן הסתכלתי (יש שם זמן ריצה הכולל)
זמן הריצה הכולל של כל php4-cgi הוא 98 שעות (שזה 6:10 כפול 16 תהליכים) בעוד ש־MySQL רץ כ־290 שעות.
שוב, בואו נפריד בין מהירות בסיס הנתונים ויעילות של השימוש בו. אם אתה חושב שתוכל לעשות אותו יותר מהיר... אתה מוזמן לנסות. רק שלא נראה לי שתצליח כי הרבה אנשים מאוד חכמים ממני וממך עבדו עליו כדי להבטיח גם ACID וגם מהירות.
מאיר,
אני מאוד מעריך את העבודה שלך ואת הדעות שלך ואני אף פעם לא אמרתי ולא ניסיתי לומר לך כיצד לנהל ווטסאפ או כיצד לבנות את היישומים שלך. כי אני יותר מבטוח שאתה יודע לעשות אותם בצורה מאוד טובה.
כל מה שאני אומר... צריך לחשוב מחוץ לקופסה והדעות המקובלות. לא כל מה שמקובל זה בהכרח טוב והפיך.
ד"א ברור לי שהשימוש בטכנולוגיה שאני מפתח עבור האתה המסכן והקטן שאני בונה הוא Overkill, אבל... יש לזה מטרות אחרות, בפרט proof of concept
*proof of concept
אני אנצל את התגובה בכדי לומר לך שאני מאוד נהנה מהבלוג שלך והדיונים בעקבות הפוסטים. אני למדתי לא מעט בזכותם =).
תודה
ראשית אני רוצה להבהיר שאין נגיעה פה לגבי או ווטסאפ. פשוט הוא שרת בעל גישות רבות יחסית אשר יש לי גישה ישירה לנתוניו.
לא הצלחתי להבין מדוע זו בעיה. זו הדרישה שיש באתר וזה מה שהוא מספק (ויכול גם יותר, ראיתי כבר).
במקרה הכי גרוע, אין לי בעיה להוסיף אופטמיזיציה, הרי זה כמעט ללא שום caching, כך שגם הקוד הזה יכול לגדול ללא בעיות מיוחדות.
לגבי "האופן שמשמשתמשים בבסיס הנתונים", זה לא בעצם האופן אלא עצם השימוש (אם "אופן השימוש בו" המומלץ הוא "לא להשתמש בו" - זה לא האופן). במקרה הזה אני מאשים את mysql ישירות - ה-scaling שלו די עלוב.
בווטסאפ קישרתי בפורום להרצאה מעניינת על שפות תכנות והמורשת שלהן. ההרצאה מתחילה בשנים המוקדמות של שפות הפיתוח - כדאי לצפות בה כדי להבין כמה אנו נמצאים בתקופת האבן - גם בהשוואה לאז.
לגבי proof of concept, לא ברור לי (להבדיל מזה שזה משהו שמעניין אותך ואתה רוצה לחקור - שזה אני מבין לחלוטין). תחילת דרכי בעולם הווב הייתה דומה, פיתחתי בשפה מהודרת (דלפי/פסקל) ובכלים הרבה יותר נוחים ותומכים ממה שמשמשים (גם אותך) כעת.
מהר מאוד הבנתי שזה לא זה אלא גיהנום בתחזוקתה וגידול, חיפשתי ומצאתי (כמו גם רבים אחרים) פתרונות אלגנטיים יותר לבעיה.
הוסף תגובה:
חובה לאפשר JavaScript כדי להגיב.