הבלוג של ארתיום
בלוג על לינוקס, תוכנה חופשית, מוזיקה, סלסה, ומה לא!
C++/C, עיבוד טקסט ומה שביניהם...
כחלק מהעבודה על CppCMS רציתי להוסיף מודול פשוט שיאפשר להכין תוכן מאמרים. לפני עמדו שתי אפשרויות:
- להכניס איזשהו מודול שצד הלקוח -- אחד מעורכי JavaScript הנפוצים שנותנים סביבת WYSIWYG "הנוחה".
- להכניס רכיב שיודע לתרגם איזשהו סוג של markdown ל-html.
הפתרון הראשון מביא מספר בעיות:
- אני לא סובל WYSIWYG באופן כללי ומתעצבן בכל פעם מחדש שאני עורך כתבות בבלוג הזה. כי יש תמיד משהו שמתנהג לא כמצופה.
- מעטים מעורכי WYSIWYG תומכים בעברית כראוי.
- מעטים מהם תומכים בכל הדפדפנים כולל Konqueror. (למשל, אני לא יכול לעבוד איתו ב-WordPress וזה די מעצבן).
אז התחלתי לבדוק את נושא markdown, כי הסימנים שלו נייטרליים לכיווניות, מה שהופך אותו לכלי מאוד אטרקטיבי לכתיבה בעברית; ובאופן כללי הוא די נוח לעבודה. כאן הציפתה לי הפתעה: לפי ויקיפדיה, ל-markdown יש מימוש ב-13 שפות החל מהנפוצות כמו PHP/Python/Perl/C#/Java ועד ליחסית אקזוטיות כמו Haskell או Lisp, אבל מה... אין C++/C. זה היה די מאכזב, אפילו שקלתי לבדוק כיצד לקרוא ל-Haskell מתוך C על מנת להתממשק עם ספריה מוכנה.
אז התחלתי לחשוב: "מה הגורם לכך ש-markdown עדיין לא מומש בשתי השפות הנפוצות האלה. ואז הבנתי שההבדל בין כתיבת parser כלשהו בשפות *P למיניהם לבין כתיבת parser כזה ב-C++/C הוא קודם כל דרך החשיבה.
נתחיל מדוגמה פשוטה:
כיצד היית כותב parser שהופך רכיב של BBCode כמו [B]טקסט[/B] לקוד html הסופי <b>טקסט</b> בשתי השפות C++/C ו-PHP/Perl?
אם הייתי כותב ב-PHP הייתי משתמש בביטוי רגולרי פשוט וכותב משהו בסגנון:
preg_replace("[b](*.)[/b]","<b>$1</b>");
אני לא מתחייב לשפה נכונה, אבל המשמעות היא די ברורה.
כיצד הייתי עושה זאת ב-C? יש לי שתי אפשרויות. הראשונה היא להשתמש באותה טכניקה בדיוק -- ביטויים רגולריי, להתממשק למשל ל-boost::regex ולעשות זאת בשתי שורות קוד בדיוק. אבל אני, שכתבתי יותר מ-parser אחד במשך חיי המקצועיים הייתי עושה זאת אחרת.
הייתי מגדיר אוטומט בעל שני מצבים: טקסט רגיל וטקסט מודגש. כשהייתי מגיע ל"[b]" הייתי כותב לפלט <b> ועובר למצב שני ובהנתן [/b] הייתי כותב </b> וחוזר למצב רגיל. למעשה, הייתי מממש את מה שהביטוי הרגולרי עשה עבורי: כי ביטוי רגולרי ואוטומט סופי הם שקולים זה לזה. אז למה לי לכתוב אוטומט? נגיע לזה בהמשך.
לא תמיד הכל כל-כך פשוט:
בואו נניח שאנחנו מאפשרים תגים מקוננים למשל "ציטוט בתוך ציטוט". במקרה כזה, השפה שלנו מפסיקה להיות רגולרית ובמקרה הטוב היא הופכת לחופשית הקשר (מי שחשב שהקורס "מודלים חישוביים" הוא מיותר טועה לחלוטין). כאן, ביטויים רגולריים לא יכולים לעזור לנו כי הם לא מספיק חזקים על מנת לפתור בעיות כאלה. ב-C++/C יש כלים שמאפשרים לעשות parsing בצורה יפה גם שפות חופשיות הקשר והם yacc/bison++/bison -- אתה כותב את הדקדוד שלך מוסיף לו קצת C ומקבל את ה-parser המושלם. אבל כלים כאלה הם קצת יותר מלהיות כלים פשוטים וקלים להבנה. כלים דומים קיימים גם עבור שפות כמו perl (אבל אני אישית לא מכיר אותם).
אז פתרנו בעיה? לא! כי markdown היא לא שפה חופשית הקשר (אומנם לא הוכחתי זו, מי שרוצה יכול בקולות להסתכל על הוכחה מדוע 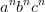 אינו חופשית הקשר על מנת להבין זאת). לכן הכלים הסטנדרטיים לא יעבדו -- צריך לכתוב אוטומט, להוסיף לו מחסנית ועוד כמה דברים ואז תקבלו את ה-parser המושלם שלכם.
אינו חופשית הקשר על מנת להבין זאת). לכן הכלים הסטנדרטיים לא יעבדו -- צריך לכתוב אוטומט, להוסיף לו מחסנית ועוד כמה דברים ואז תקבלו את ה-parser המושלם שלכם.
אז למה עדיין אין parser עבור markdown ב-C?
כי אנשים רגילים לחושב במושגים של ביטוים רגולריים. אם תקראו קוד של php-markdown, למשל, תראו עשרות פעולות גלובליות על הטקסט -- לעשות שינויים בכל טקסט, להחליף א' ב-ב' ועוד. לממש את ה-parser בהרבה שורות מורכבות המבוססות על ביטויים רגוליים שהופכים את הקוד לאיטים לקשה לקריאה והבנה.
כך כותבים רוב האנשים שבאים מרקע של שפות *P. לולאות זה יקר, ביטויים רגולריים זה מהיר.
לעומת זאת, אם הייתי כותב ב-C. הייתי כותב אוטומט מצבים, מתאר מה כל מצב שלו אומר ומתאר את המעברים. הקוד היה ארוך יותר, אבל הוא היה הרבה יותר נקי מבחינת הגדרה מדוייקת, הרבה יותר צפוי וכנראה יותר נקי מבחינת באגים.
לי, באופן אישי, יצא לכתוב לא מעט parserים שכולם התבססו על אוטומט מצבים. ואני יכול להגיד שזה לא הרבה יותר מסובך או אפילו יותר פשוט מאשר לכתוב ביטוי רגולרי, רק שזה הרבה יותר יעיל, נקי, ומסודר.
הכל זו דרך חשיבה: לדחוס את הכל לכמה ביטיים רגולריים מסובכים וקשים לקריאה והבנה למי שמתחזק את הקוד; או לתאר אוטומט מצבים אולי קצת יותר ארוך ולממש אותו -- ובכך להרוויח את הגמישות של הקוד.
כתבתי מימוש חלקי מאוד של markdown תוך מספר שעות ב-C שעדיין לא כולל רכיבים מקוננים. אבל תומך בלא מעט דברים כמו ציטוט, קוד, רשימות כותרות פיסקאות קישורים ועוד. בהמשך אני אוסיף לו מחסנית שתאפשר להרחיב אותו ל-markdown היותר מלאה הכולל רכיבים מקוננים. (לא עשיתי זאת, רק מפני שהייתי זקוק ל-demo מהיר). הקוד הוא חלק מה-cppcms נמצא בקבצים text_tool.cpp/h.

תגובות
ללהק בחרתי להשתמש ב-reStructuredText הממומש בפייתון בעזרת docutils.
זה לא ממומש בצורת ביטויים רגולריים, אלא לשלב ביניים של עץ XML, המאפשר תנועה לאורך הענפים השונים וביצוע דברים יפים בצורה תכנותית, כמו גם הרחבות, יכולות תרגום directives (היה לי חשוב מאוד, מאחר וערבוב directives אנגליים בעברית זה מתכון לבלאגן בעריכה).
את העץ לאחר מכן ניתן לייצא לפורמטים שונים (כגון Latex ו-S5 למצגות), כאשר html הוא העיקרי: http://docutils.sourceforge.net/docs/dev/hacking.html
reStruturedText ו-MarkDown הם די זהים. אם היה מימוש של reStructuredText ב-C++/C הייתי בוחר בו. בנוסף, אני גם לא מממש את markdown כפישהו, כי יש בו הרבה רכיבים שמקשים על בניית parser בסגנון LR1, קרי אני לא רוצה לזכור 50 צעדים לאחור על מנת לבחליט משוה.
ברור ששיטת המרה של טקסט למבנה ביניים והמרה שלו ל-HTML/LaTeX זה כלי מאוד יעיל. ואולי בשלב מאוחר יותר אני אטפל גם בזה.
לגבי parsing עצמו. עד היום לא נמצאו הרבה שיטת -- כולן בסופו של דבר מגיעות למכונת מצבים עם זכרון זה או אחר. אני מניח שגם docutils משתמשים בזה (אולי בצורה מתוחכמת).
ד"א אם אתה מתכוון להשתמש בלהק בייצוא של restructured text ל-LaTeX צפה לבעיות עם עברית.
כמובן שאני לא בונה על הייצוא ל-Latex. באופן אישי הגעתי למסקנה ש-Latex לא שווה את המאמץ עבורי. הוא בעייתי עם עברית (מבחינת התקנה הגדרה וטון החבילות שהוא מושך) גם ללא קשר לייצוא, שאני מעדיף לא להכנס לכך. את רוב התיעוד שלי אני כותב ב-reST ומייצא ל-html לאחר מכן (זה גם נבחר להיות גם התחביר בתיעוד הרשמי של פייתון מהגרסאות הקרובות).
פשוט הדגמתי שהגישה של "בשפות P עושים ב-regex" לא ממש נכונה. זה תלוי במפתח ולא בשפה.
נ.ב. נכון שכתבת שאתה לא מתחייב, אך ה-regex שלך שגוי וגם greedy ;-)
מסכים, אבל ראיתי יותר מידי קוד שעושה שימוש בביטויים רגולריים מורכבים מאוד בשביל להשיג את המטרה. אחת מהסיבות היא שמקובל לחשוב:
שוב, אני לא מנסה להלביש כותבי בשפות P בלבוש של כותבי regex. מפתח טוב ויפתח טוב גם ב-*P וגם ב-C. גרוע... לא צריך להסביר.
העניין הוא ש-C נחשב לשפה מאוד לא ידידותית לכתיבה parsers למיניהם ועבודה עם טקסט. (היית צריך לשמוע מה אמרו לי כשכתבתי biditex ב-C)
זה לא נכון, זה לא מסובך לכתוב text parsing ב-C++/C -- אפילו מאוד פשוט, רק צריך לחשוב במונחים של אוטומטים ולא מונחים של ביטויים רגולריים.
לי אישית, הרבה יותר קל לעשות הרבה דברים ב-++C מאשר בשפות *P גם כי אני מכיר אותם לא מספיק טוב וגם כי יותר קל לי לחשוב במונחים של אוטומטים.
אני יודע ;) סתם רציתי להמחיש את הרעיון
אני בעד מה שמתאים זה מה שייכנס. בלהק שילבתי בין השניים (לולאות ו-regex) מאחר ויש לי preprocessors ו-postprocessors שרצים לפני ואחרי ה-rest (הוספתי פרוטוקולים מיוחדים, thumbnail מיוצר אוטומטית כאשר מבקשים גודל תמונה מסויים וכן הלאה). לא הכי מסודר כמו שהייתי רוצה, אך עדיין עושה את העבודה:
http://lahak.python-hosting.com/browser/trunk/vertical/rest
במקרה שלך זה שונה, כי כבר יש תשתית קיימת שצריך להתלבש עליה.
ואני בהחלט מסכים שצריך לראות כל מקרה לגופו. כך למשל, ב-urls עבור cppcms השתמשתי בביטויים רגולריים כי זה מה שמתאים שם.
ד"א אם אנחנו כבר מדברים על reStructuredText ועברית, מה עשית עם סימני כיווניות? כלומר מה משמש אותך בלהק בתור תגי rtl/ltr?
ל-reST יש יכולת להחיל סגנון לאלמנט הבלוק הבא בתור. כך שהגדרתי שני סגנונות: ltr ו-rtl, וניתן להחילם על הטקסט בצורה שכזו:
.. סגנון:: ltr
english goes here this is the same block
כיווניות חוזרת לרגיל
ואותו הדבר לכיוון ההפוך.
תודה, האם הוספת ל-reST אפשרות לעשות משהו בסגנון עבור חלקים מסויימים באותו בלוק, למשל, משהו כזה:
הופך ל:
זה היה יכול לעזור מאוד ;) חשבתי עם יש syntax עובר דברים כאלה.
reST כמעט לא עובד על תגים פותחים/סוגרים במובן הקלאסי, זו גם הסיבה שהוא מאוד קריא גם בתור קוד מקור.
לא חשבתי על משהו כזו, במקרים שנדרשתי להם אני פשוט מוסיף את תווי הכיווניות של הקידוד עצמו (shift+א ו-shift+ט בתת-פריסה lyxעבור מקלדת עברית) וזה די עונה על הצורך.
אם איישם זאת אצטרך לחשוב על משהו שלא מפריע ל"זרימת" הטקסט במצב עריכה.
או קיי, נכון... תודה :)
לדעתי דווקא העורך הזה נחמד אבל אם לך כוח אליו או משו יש הרבה עואכים חינמיים ברשת כנס לhotscripts ויש שמה מלא...
על איזה עורך בדיוק אתה מדבר?
יש לי ניסיון מר עם רוב עורכי WYSIWYG שיצא לי להשתמש בהם - במיוחד כשמדובר בעברית.
בנוסף, אני צריך שהרישיון של העורך יהיה חופשי (GPL/BSD/MIT) ולא רק חינמי, חוץ מזה העורך WYSIWYG הראשון שראיתי באתר שקישרת אליו, עלה לא מעט כסף, (שלא לדבר על רישיון הפצה חופשי).
לגבי עורך WYSIWYG, יש את העורך של Yahoo: http://developer.yahoo.com/yui/editor/
(תחת רשיון BSD) בכלל, כל ספריית ה javascript שלהם (YUI) מאוד טובה.
נראה לי שבסופו של דבר, עורכי WYSIWYG (אם הם עובדים כמו שצריך) נוחים לרוב הציבור, ושפות מרק-אפ שונות נוחות יותר לציבור המתכנתים.
קודם כל, יש מספר בעיות עם WYSIWYG:
(כך מה שכתבתי היה כאן היה אוטומטית הופך לרשימה ב-MarkDown.
נ.ב. העורך שהפנית אליו לא עובד לי משום מה לא באפיפני ולא בקונקי.
הוסף תגובה:
חובה לאפשר JavaScript כדי להגיב.