הבלוג של ארתיום
בלוג על לינוקס, תוכנה חופשית, מוזיקה, סלסה, ומה לא!
מאמרים בנושא תכנה חופשית.
השוואת FPC ושפות אחרות
נתחיל מהטבלה שמשוואה מספר שפות תכנות פופולריות: Python, Java, C, C++ ו־FPC. כאשר אני מתמקד במספר רבדים: תכונות שפה מרכזיות, סגנונות פיתוח ותכנות אפשריים, ספריות וספקים.
השוואה לפי תכונות:
| Feature | Python | Java | C | C++ | FreePascal |
|---|---|---|---|---|---|
| Core: | |||||
| Memory man. | Automatic | Automatic | Manual | Semi-Automatic | Manual |
| Resources man. | Automatic1 | Manual | Manual | Semi-Automatic | Manual |
| Inheritence | Multiple | Sinlge | No | Multiple | Single |
| Polymorphizm | Duck | Dynamic | No | Dynamic+Static | Dynamic |
| Reflection | Yes | Yes | No | No | No |
| Language Features | |||||
| Generic Programming | Irrelevant | Limited | No | Turing Complete | Limited |
| Generic methods | Irrelevant | Yes | No | Yes | No |
| Requires interfece | Irrelevant | Yes | - | No | No |
| Functional Programming | Yes | Very Limited | No | C++03 Limited C++0x Full | None |
| Libraries: | |||||
| Standard: | Rich | Rich | Poor | Limited | Rich |
| conteiners | Yes | Yes | No | Yes | Yes |
| threading | Yes | Yes | No | No | Yes FCL |
| GUI | Yes | Yes | No | No | Yes LCL |
| 3rd party libs.: | Rich | Rich | Rich | Rich | Poor |
| Other: | |||||
| Standards | None | Yes | Yes | Yes | Outdated |
| Implementations: | CPython, Jthon, IronPython | GNU, Sun, IBM | Lots | Many: GNU, MS, HP, Sun, Intel... | Single |
| Defacto-Vendor | Yes: CPython | Yes: Sun | None | None | FPC |
| Performance | Poor | Medium | High | High | High |
הערות:
- רק ב־CPython.
סיכום:
- Python: נותנת לעבוד עם כל סגנונות פיתוח אפשריים, קל לפיתוח וניהול משאבים, אבל סובל משתי בעיות עיקריות: ביצועים ו־vendor lock in.
- Java: שפה יחסית מגבילה מבחינת הגישה שלה, אבל בטוחה לפיתוח ותכנות בזכות: GC, ספריה סטנדרטית מאוד עשירה פשטות השפה.
- C: שפה שכמטע ולא מספקת כלים "מודרניים"... כבודה במקומה מונח, ועדיין יש לה המון יישומים במיוחד בתחום embedded, או כל תחום אחר בו צריך לרדת לרמת תכנות נמוכה ולשמור על קומפקטיות וקריאות של הקוד.
- C++: שפה מאוד עשירה, הרכיבים המודרניים היחידים שחסרים לה זה: העדר Reflection, העדר GC מלא (אם כי ב־C++ RAII מחליף אותו בהצלחה) ואולי צורך בספריות צד ג'. כמובן עם הכוח בא גם החיסרון: שפה מסובכת שלוקח זמן ללמוד אותה לעומק ולהבין את הרבדים השונים שלה.
- עכשיו הגיע תורה של FPC: היא נמצאת איפשהו בין C לבין Java:
- מצד אחד, אין לה GC ומצד שני אין לה גם RAII שיש ב־C++, ניהול המשאבים שם ידני לחלוטין ממש כמו ב־C.
- יכולות הירושה מוגבלות לירושה בסגנון C#/Java.
- תמיכה ב־Generics מוגבלת, אין תכנות פונקציונלי (במובן lambda calculus) וגם אין Reflection.
- ספריה סטנדרטית די עשירה (אם לוקחים גם FCL ו־LCL), אבל העדר ספריות צד ג' כואב, הרבה יותר
נשאלת השאלה: מהו הערך המוסף ש־FreePascal נותנת מעבר לתחביר שנחשב לקצת יותר קריא? נדמה שלא הרבה.
לרגל שחרורו של gcc-4.4... חידושים ושיפורים.
לפני כחודש שוחררה גרסה חדשה של gcc: 4.4. אחד הדברים המעניינים זה התקדמות בתמיכה בתקן C++ החדש C++0x. הנה כמה תכונות מאוד מעניינות שכבר מזמן חיכיתי להן:
סוף־סוף, הגיע אחת התכונות הנחשקות ביותר --- תמיכה ב־auto, שחוסכת המון הקלדה מיותר ומקלה בצורה משמעותית על כתיבת קוד בלתי תלוי בקונטיינרים. לדוגמה, היום כך כותבים לולאה שמדפיסה איברי הרשימה:
for(list<int>::contst_iterator p=numbers.begin();p!=numbers.end();++p) { cout<< *p <<endl; }ואם רוצים לשנות את סוג הקונטיינר מ־list ל־vector צריך לשנות את
listל־vectorבלולאה. עם טיפוס auto זה מתקצר בצורה משמעותית:for(auto p=numbers.begin();p!=numbers.end();++p) { cout<< *p <<endl; }ובנוסף ל"קיצור" הכתיבה, אין שום אזכור של סוג הקונטיינר בלולאת for.
טיפוסי תווים חדשים. בסטנדרט הנוכחי יש בעיה משמעותית בהגדרת תווי unicode, או ליתר דיוק העדר הגדרה ראויה שלהם. כך
wchar_tלמעשה יכול להיות בגודל של 32 ביטים, 16 ביטים ואפילו 8 ביטים. למעשה, בסביבת Windows, wchar_tהוא בגודל של שני בתים ומייצג utf-16 (או ucs-2), כאשר בכל סביבות ה־UNIX, wchar_tמייצג נקודת קידוד בודדת והוא בגודל של 32 ביט. זה יוצר לא מעט בעיות בטיפול במחרוזות unicode. כי הקידוד של std::wstring לא ברור.התקן החדש הגדיר שני טיפוסי תווים חדשים:
char16_tו־char32_tשמונעים את האי בהירות בנושא. כך שהעבודה עם std::u16string ו־std::u32string הופכת להרבה יותר שקופה. כך, בנוסף הוגדר ייצוג חדש למחרוזות:std::string normal="שלום"; // encoded as 8 bit std::wstring wide=L"שלום"; // utf16 or utf32 depending on your OS std::u16string utf16=u"שלום"; // utf16 encoded std::u32string utf32=U"שלום"; // utf32 encodedכמובן, לא צריך לשכוח את התמיכה ב־Variadic templates שהתווספה ב־gcc-4.3, המאפשרת לבנות פונקציות typesafe עם מספר משתנה של פרמטרים בצורה בטוחה, קצרה ומהירה. התמיכה בהן מקצרת בצורה בסדר גודל את זמן הקומפילציה של תבניות כמו std::function או std::bind.
מבחינתי, יש עוד מספר תכונות שאני מחכה להן:
- תמיכה בביטויי למבדא.
- תמיכה ב־delegating and inheriting constructors שמקצרת בצורה משמעותית את הכתיבה של overloaded constructors.
- תמיכה ב־Concepts שייאפשר לספק פלט שגיאות הרבה יותר ידידותי.
- תמיכה מלאה ב־STL החדש, כולל regular expressions.
אני מקווה שזה לא ייקח הרבה זמן...
ייסורי Unicode ב־2009, או תמיכה ב־unicode בסביבות שונות.
אחד הדברים החסרים ביותר ב־C++, מבחינתי, זה העדר תמיכה טובה ב־Unicode. למרות ש־std::wstring ו־std::locale קיימים הם לא נותנים מענה על כל דרישות העבודה עם Unicode.
יש שפות תכנות כמו Python ו־Java בהן התמיכה הזו נחשבת ל"טבעית". אז החלטתי לעשות בדיקה ולבדוק מספר דברים חיוניים בעיבוד טקסט טבעי: החלפה בין אותיות גדולות וקטנות וכן מציאת גבולות המילים. דברים שנראים טריוויאליים עבור אנגלית למעשה הופכים לכלל לא טריויאליים כאשר מדובר בשפות אחרות:
- שינוי אות קטנה לגדולה: ß גרמנית צריכה להפוך ל־SS (שתי אותיות).
- שינוי אות גדולה לקטנה: Σ היוונית הופכת ל־σ במרכז המילה ול־ς בסופה.
- הפרדת מילים לצורך חיתוך הטקסט: 中文 אלה שתי מילים ולא מילה אחת.
בדקתי 6 כלים: ספריית ICU עם API במספר שפות, ספריית glib יחד עם pango עבור C, ספריות Qt3 ו־Qt4 עבור C++, וגם כלים טבעיים של Java, C++ ושל Python.
אקדים ואומר, המקרים הפשוטים כמו המרת: "Артём" (השם הפרטי שלי ברוסית) ל"АРТЁМ" עבדו בכל הכלים ושפות, אבל במקרים יותר מורכבים התוצאות היו כלל לא מעודדות:
| כלי | לאותיות גדולות | לאותיות קטנות | גבולות המילים |
|---|---|---|---|
| C++ | נכשל | נכשל | אין תמיכה |
| C++/ICU | הצליח | הצליח | הצליח |
| C++/Qt4 | הצליח | נכשל | הצליח |
| C++/Qt3 | נכשל | נכשל | אין תמיכה |
| C/glib+pango | הצליח | הצליח | נכשל |
| Java/JDK | הצליח | הצליח | נכשל |
| Java/ICU4j | הצליח | הצליח | הצליח |
| Python | נכשל | נכשל | אין תמיכה |
| Python/PyICU | הצליח | הצליח | הצליח |
עכשיו פרטים
המשך...האם בסיס הנתונים הוא צוואר הבקבוק של המערכת?
אחת הדעות המקובלות בקרב מפתח Web היא שבסיס הנתונים הוא צוואר בקבוק של המערכות. בסופו של דבר, אם יש המון נתונים והחיפוש לוקח 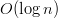 אז אין מה לעשות. ברמה תיאורתית זה נכון.
אז אין מה לעשות. ברמה תיאורתית זה נכון.
אם יש לך בסיס נתונים של 1,000,000Gb (שזה 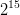 ) אז כנראה החזקה מספיק גדולה ואין משמעות לטכנולוגיות אחרות... השאלה היא האם זה נכון?
) אז כנראה החזקה מספיק גדולה ואין משמעות לטכנולוגיות אחרות... השאלה היא האם זה נכון?
כידוע, מודל הסיבוכיות הוא עובד יפה כשמדובר במספרים גדולים מספיק ונוהג להתעלם מקבועים. מסתבר שהקבועים הם מספיק חשובים.
כדי להבין את זה, נקח כדוגמה את אחד הפרוייקטי ה־web הגדולים --- wikipedia או ליתר דיוק את חוות השרתים של wikimedia.
נתונים גולמיים:
- בחוות השרתים נמצאים כ־300 שרתים שונים.
- מתוכם במסלול הראשי:
- 95 שרתי Squid -- מה שנקרא Upstream cache שנותנים מענה לכ־78% מכל הבקשות (hit ratio שלהם).
- 144 שרתי Apache+PHP. שנותנים מענה ל־25% הנותרים.
- 20 שרתי MySQL שונים הרצים בתצורות Master Slave השונות.
- השרתים האחרים נותנים מענה לחיפוש, טיפול בקבצים סטטיים ועוד.
- מנגנון memcached משפרים ב־7% הנוספים את היעילות של יצירת התוכן ע"י שרתי Apache.
לכן כיצד שרתי SQL יכולים להוות צוואר בקבוק של המערכת אם הם מהווים פחות מ־10% מכל השרתים הקיימים בחווה? בהנחה שהמערכת שנבנתה ע"י media wiki היא מאוזנת, ברור לנו שרוב העומס החישובי נופל דווקא על שרתי apache המריצים את PHP.
אז האם באמת בסיס הנתונים הוא צוואר הבקבוק?
יותר מחשבים יותר ביצועים?
כשבניתי CppCMS תמיד לקחתי בחשבון ששרת יחיד לא תמיד יוכל להבטיח ביצועים מספיק טובים של שירות web עמוס. לכן, תמיד בתכנון המערכת, לקחתי בחשבון את האפשרויות של scale up.
בהחלט, הרבה יותר קל לתכנן מערכת שרצה על מחשב בודד עם זכרון משותף עם cache נגיש בצורה יעילה ועוד. אבל, במציאות זה לא יכול להיות. מערכות שמסוגלות לעמוד בעומסים גובהים הן בסופו של דבר חייבות להיות מוכנות לפעול בצורה מבוזרת.
לאחרונה הצלחתי להשיג גישה זמנית לרשת מחשבים חזקים במיוחד: Intel עם 4 ליבות שרצים ב־2.4GHz ו־4GB של זכרון. כך יכולתי לבדוק את מנגנון ה־cache המבוזר בעובד מעל TCP/IP ולהבין כמה אני מפסיק כתוצאה מביזור:
# Local Distributed
1 5,500 5,500
2 11,500 9,500
3 15,200 13,500
הטבלה מציגה את מספר הדפים בשניה שהמערכת wiki שבניתי מסוגלת לספק תחת הנחה של פגיעה 100% ב־cache (בגלל אילוצי הגישה לא יכולתי לשנות את הפרמטר). מספר השרתים הוא בין 1 ל־3 ומנגנוני ה־cache הם: cache המקומי הלא־מסונכון ו־cache המבוזר המסונכרן באופן מלא.
אפשר לראות, מחשב בודד מסוגל לייצר כ5 וחצי אלפי עמודים בשניה והמספר הזה הולך וגדל בצורה קרובה ללינארית עם שימוש ב־cache מקומי (כצפוי). שימוש ב־cache המבוזר מעל TCP/IP מקטין את מהירות הכוללת של המערכת אך עדיין שיפור ביצועים נשאר קרוב ללינארי.
יש לציין שהצלחתי למלא כמחצית מרוחב הפס של רשת 1GBit.
כמובן הניסוי הוא די מלאכותי, אבל הוא נועד בעיקר לבדוק עד כמה מנגון ה־cache המבוזר הוא יעיל. אני לא מביא לכאן פרטים מדויקים של ניסוי מפני שהוא היה יותר ניסוי פנימי, אבל בסה"כ הוא נותן הבנה של סדרי הגודל של מה שהמערכת מסוגלת לספק.

{kind=link}